在數字化轉型浪潮席卷全球的今天,企業積累了海量的數據資產。許多企業在數據應用的道路上,往往面臨著“最后一公里”的困境:數據處理能力強,但數據價值交付難。數據服務化,正成為打通這“最后一公里”的關鍵路徑與核心引擎。
一、何為數據服務化?
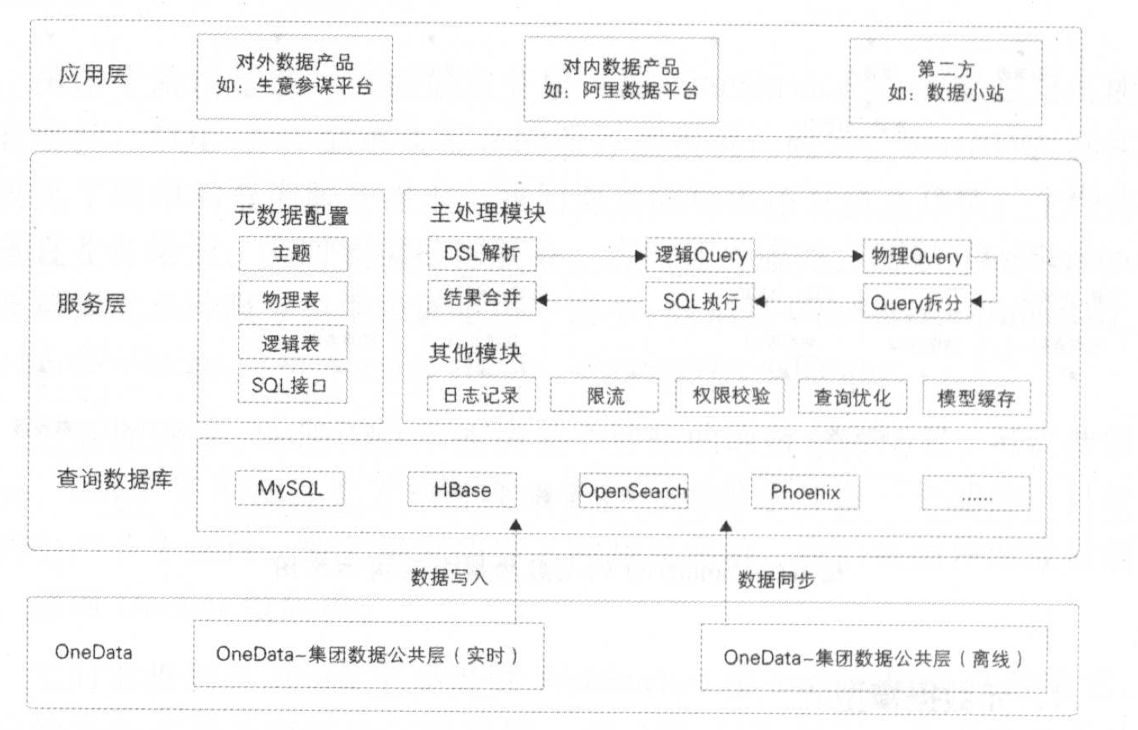
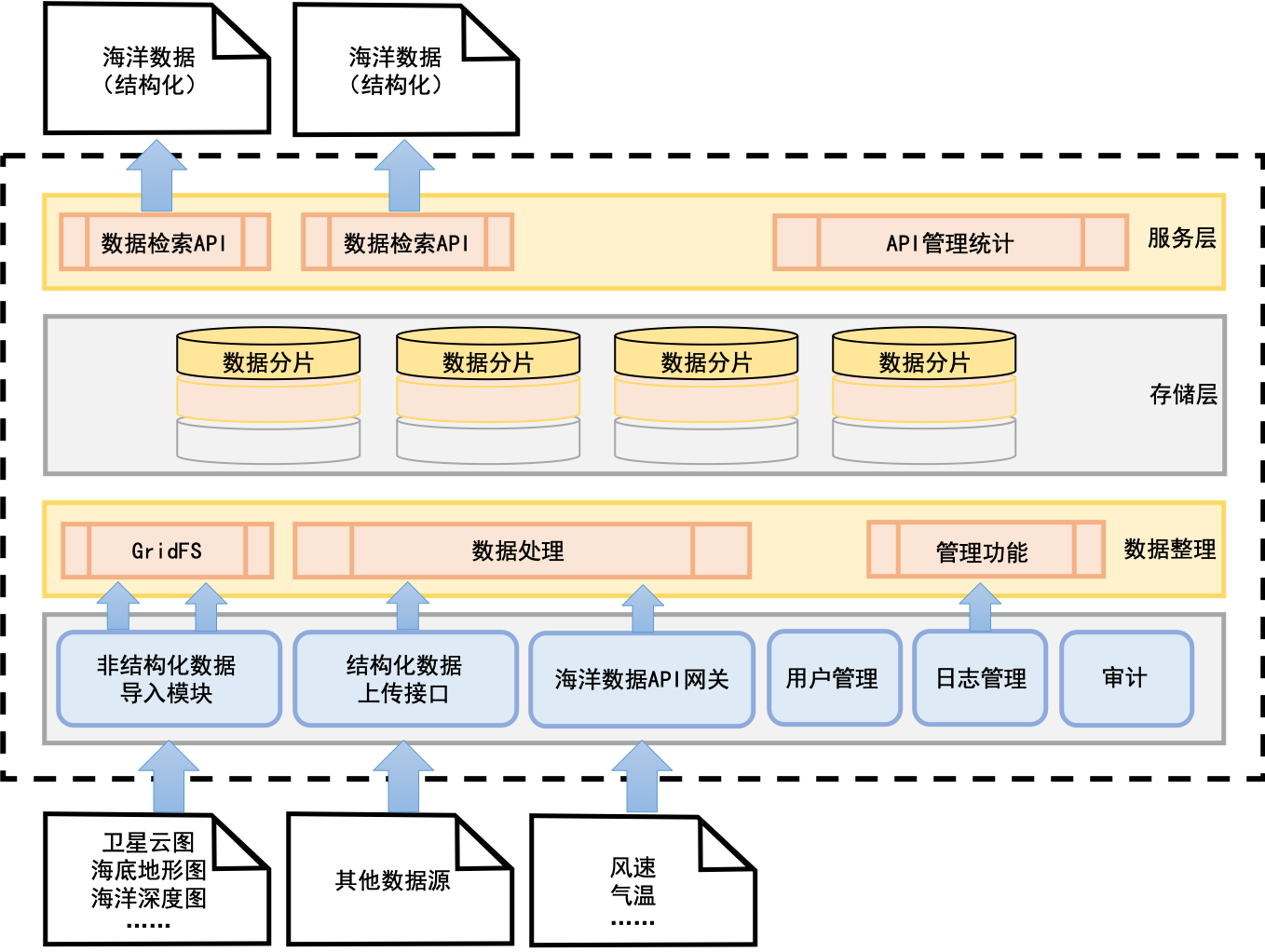
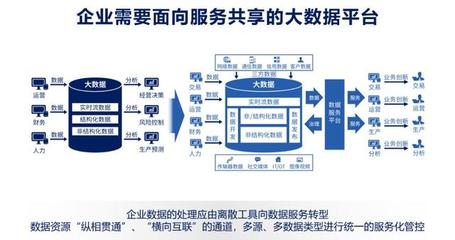
數據服務化并非一個全新的概念,它代表著一種將數據從靜態的、孤立的“資源”轉變為動態的、可被便捷調用和消費的“服務”的核心理念與實踐。傳統的數據處理流程,如ETL、數據倉庫建設,主要關注數據的整合、清洗與存儲,其產出物是報表、指標或數據集。而數據服務化則更進一步,它將這些處理后的數據封裝成標準的、可復用的API接口或微服務,使得業務系統、應用程序乃至合作伙伴能夠像調用水電煤一樣,按需、實時、安全地獲取所需的數據能力。
數據處理服務是數據服務化落地的具體承載。它不再僅僅是一個后臺的、批處理的任務,而是演變為一套標準化的、可管理的服務體系。這套體系負責將原始數據經過加工、計算、封裝,最終以服務的形式對外提供,其核心目標是降低數據消費的技術門檻,提升數據價值的流通效率。
二、為何需要數據服務化?
企業數據應用的“最后一公里”障礙,主要體現在以下幾個方面:
- 響應慢,時效差:傳統批量報表模式無法滿足實時決策、個性化推薦等場景的即時性需求。
- 煙囪林立,復用難:各業務線重復開發數據接口,標準不一,形成新的數據孤島,造成資源浪費和維護成本高昂。
- 消費門檻高:業務人員或前端應用開發者需要深入理解底層數據模型和技術細節才能使用數據,協作效率低下。
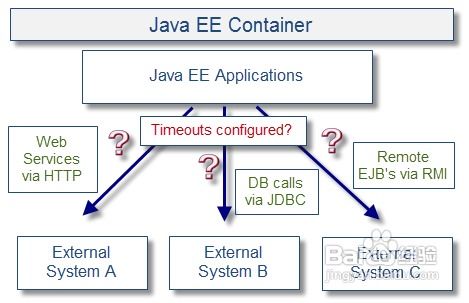
- 安全與管控薄弱:數據直接暴露或通過非標準方式傳遞,存在泄露風險,且訪問權限難以精細化管控。
數據服務化正是針對這些痛點的系統化解決方案。它通過建立統一的數據服務網關,實現數據的“一次加工,多次服務”,確保數據口徑一致;通過標準API提供實時或準實時的數據訪問,支撐敏捷業務;通過服務鑒權、流量控制、監控審計等手段,構建起堅固的數據安全與運營防線。
三、如何構建數據處理服務?
成功實施數據服務化,構建高效可靠的數據處理服務,需要體系化的建設:
1. 架構層面:微服務與API網關
采用微服務架構思想,將不同的數據處理邏輯(如用戶畫像查詢、實時風控指標計算、商品推薦模型調用)封裝成獨立的微服務。前端通過統一的API網關進行訪問,網關負責路由、認證、限流、監控等通用功能,實現服務治理的統一化。
2. 能力層面:分層與解耦
數據處理服務通常可分為三層:
- 基礎數據服務:提供對核心實體(如客戶、產品、訂單)的原子性查詢,確保數據的準確性與一致性。
- 聚合計算服務:基于業務場景,將基礎數據進行關聯、統計、聚合,提供開箱即用的業務指標(如月度銷售額、用戶活躍度)。
* 智能決策服務:集成AI/ML模型,提供預測、分類、推薦等高級數據智能能力。
各層服務解耦設計,支持獨立開發、部署和擴展。
3. 技術層面:流批一體與云原生
利用Flink、Spark等流批一體處理框架,使同一套邏輯既能處理歷史數據,也能處理實時流數據,簡化技術棧。擁抱云原生技術(容器化、Kubernetes、服務網格),實現數據處理服務的彈性伸縮、高可用和高效運維。
4. 運營層面:全生命周期管理
建立數據服務的目錄市場,讓服務可被發現、理解和申請。實施從服務設計、開發、測試、部署、上線、監控到下線歸檔的全生命周期管理。持續監控服務性能(如響應時間、可用性)和使用情況(如調用量、熱門服務),并據此進行優化和迭代。
四、價值與未來展望
數據服務化將為企業帶來顯著的商業價值:
- 加速創新:業務團隊能快速獲取數據能力,試驗新想法,縮短產品上市周期。
- 降本增效:消除重復開發,提升數據團隊產能,讓數據工程師更專注于高價值的數據加工與模型構建。
- 提升體驗:支撐更實時、更個性化的客戶交互與內部決策,直接提升用戶滿意度和運營效率。
- 釋放價值:讓數據在安全可控的前提下,在企業內部甚至生態伙伴間順暢流動,最大化數據資產價值。
數據服務化將與DataOps、AIOps等理念深度融合,向更加自動化、智能化的方向發展。數據處理服務將不僅僅是數據的“搬運工”和“計算器”,更將成為企業智能業務系統的“中樞神經”,動態協調數據、算法與業務需求,持續驅動企業跨越數據應用的“最后一公里”,駛入數字化轉型的快車道。